Surviving the Flash Sale: My Journey from a Fragile Monolith to a K8s Distributed System
When I first sat down to build a backend engine, the goal seemed straightforward: build a system that can sell 1,000 iPhones to 10,000+ highly eager users during a "Flash Sale."
How hard could it be, right?
It turns out, handling massive, concurrent checkout traffic without overselling your inventory or crashing your server is one of the hardest problems in backend engineering. This is the story of how I built the Distributed-Flash-Sale-Engine, hit a massive brick wall, and completely re-architected my system to survive the chaos.
Chapter 1: The Naive Beginnings (Nov 22 - 24)
I started where most developers start: I built a standard monolithic API using Node.js and Express, connected it to MongoDB, and wrote a simple /buy endpoint.
But I immediately ran into my first major logic bug: The Race Condition.
Imagine two users, Mayur and Prerana, clicking "Buy" at the exact same millisecond. The server checks the database for both of them simultaneously.
"Are there any iPhones left?" -> Yes, 1 left.
Both users pass the check.
Both users decrement the stock.
The stock becomes
-1. I just sold a phone I don't have.
To fix this, I had to drop down to the database level and implement strict ACID transactions to ensure that checking the stock and buying the item happened sequentially, never overlapping.
Chapter 2: Caching & Crashing (Nov 30 - Dec 6)
The database was safe, but it was slow. Checking MongoDB for every single click was heavy. To speed things up, I integrated Redis.
Instead of a two-step "check then buy" process, I used Redis atomic locks (specifically the DECR command). This allowed the system to decrease the stock and check the new number in a single, unbreakable memory cycle. If the result was negative, the system threw an "Out of Stock" error instantly.
(Side note: I ran into a horrible infinite reconnect bug with Redis due to how I mounted my Docker volumes, but eventually squashed it!)
Feeling confident, I wrote a "Nuclear" load testing script using k6 to simulate a massive spike in traffic.
The result? The system absolutely burned to the ground.

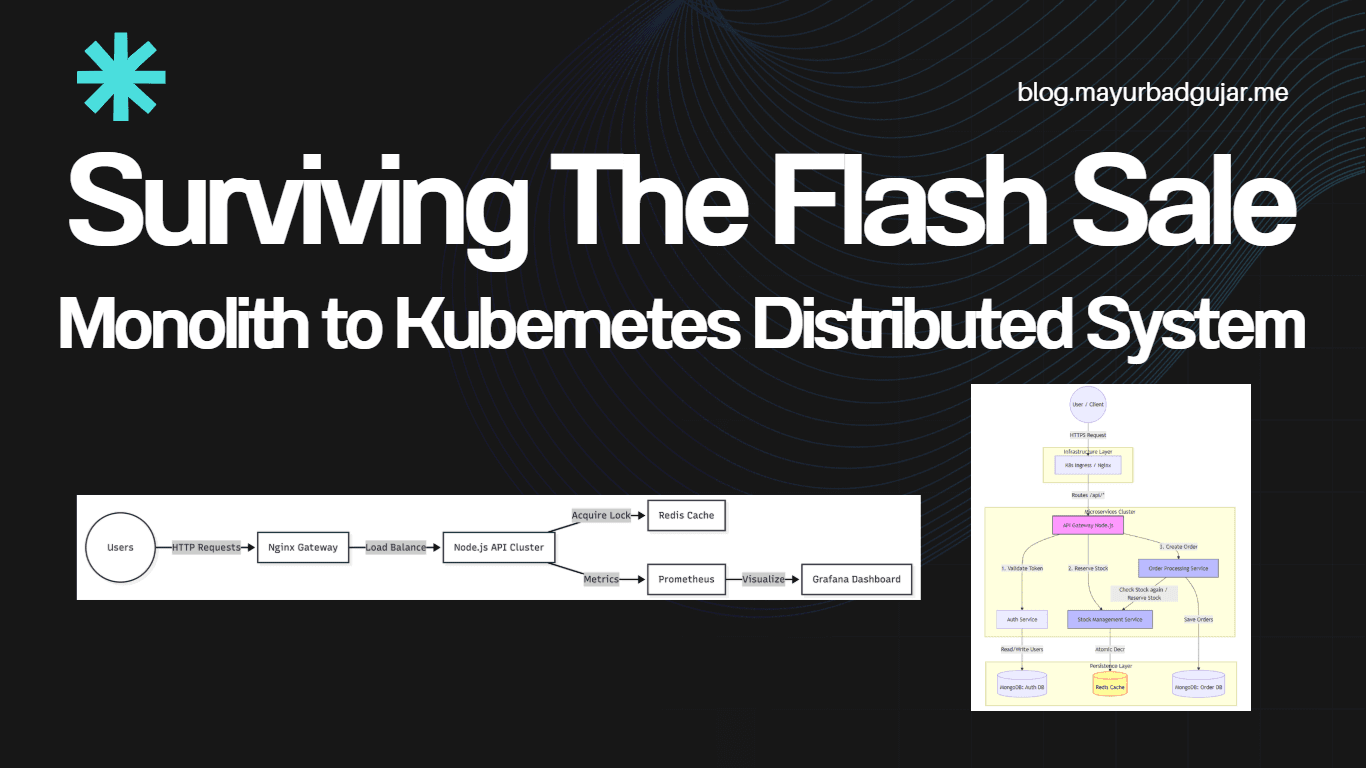
Why did it crash? Because I was using a Monolithic Architecture. Everything, user registration, stock checking, and order processing, lived inside one big Node.js process. When thousands of simulated users tried to register for the sale, hashing their passwords (bcrypt) ate 100% of the CPU. The server was so exhausted doing math that it couldn't process a simple stock check.
The checkout system wasn't broken; it was just starved of CPU by the authentication system.
Chapter 3: The Great Migration (Dec 19 - 21)
I realized that to scale the "Order" feature in a monolith, I had to duplicate the entire application, which wastes a ton of RAM. I needed to split the code up.
I spent the next few days tearing the monolith apart into a Microservices Architecture.

I built a Node.js API Gateway to route traffic and separated the core logic into three distinct apps:
Auth Service
Stock Service
Order Service
In theory, this was beautiful. In practice, making these separate Docker containers talk to each other over a virtual network was a nightmare. I spent hours debugging inter-service HTTP calls and fixing Docker environment variable injections. But eventually, the services were communicating.
Chapter 4: Kubernetes & The Final Boss (Dec 22 - 23)
Docker Compose is great for local development, but to handle a real Flash Sale, I needed serious infrastructure. I moved the entire ecosystem into a local Kubernetes (K8s) cluster using Docker Desktop. I wanted to see exactly how much traffic my own machine could orchestrate before breaking.
The secret weapon here was the HPA (Horizontal Pod Autoscaler). I gave Kubernetes a simple rule: "If any service uses more than 50% of its CPU, instantly create a clone of it to handle the load."
It was time for the final boss. I fired up the k6 stress test: 200 concurrent users relentlessly hitting the system for 2 minutes straight.
The terminal logs were insane. The Auth Service got hit so hard by the heavy cryptography of password hashing that its CPU usage spiked to an unbelievable 1439%!

But the system didn't crash.
Kubernetes saw the Auth Service screaming for help and instantly scaled it from 1 pod to 5 pods (the max limit I set).
Benchmarking revealed exactly when the system needed help:
The heavy Auth Service required a new server every ~9 requests per second.
The complex Order Service scaled up every ~12 RPS.
The lightweight Stock Service scaled up every ~14 RPS.
Because the domains were isolated, the chaos in the Auth service didn't affect the rest of the app. While Auth was fighting for its life, the Stock Service was casually serving requests with a lightning-fast 10ms latency and a 100% success rate.

Conclusion
Building this engine was a massive reality check. It taught me that writing the code is only half the battle.
Real backend engineering is about assuming that traffic will spike, servers will choke, and things will break. Moving from a fragile Monolith to a K8s Distributed System taught me the true value of Decoupling. When you isolate your services, a massive traffic spike on your login page won't prevent your active users from checking out.
The Flash Sale Engine survived, and I walked away with a profound respect for system design. 🚀